夏天吃西瓜!
基于前向和后向最大匹配算法以及贝叶斯算法进行自然于然处理中的分词处理。什么是分词呢?很简单。比如:一句话“我在清华打游戏。”由于中文不像英文,词与词之间会分隔。“I am playing game in TsingHua University.”而自然语言处理过程中,有很多情况下都是基于词语进行分析,比如:舆情分析等等。因此,我们需要应用一些算法来使得计算机能够将中文语句分割成一个个词语,从而进行进一步分析。之前那句话的分词结果就是“我/在/清华/打/游戏/。”当然,根据分词词语粒度的不同,有不同的分词结果。
接下来,分别介绍不同分词算法的原理和计算流程。
1.贝叶斯分词算法
step1 导入词典,词典中有三列数据,分别为:词汇、对应的频数、词性(稀疏形式),导入词汇及其对应频数,统计词典中所有词汇的总频数和d[‘N’]。
step2
将进行分词处理的字符串传入分词函数。从最后一个字符开始不断向前推进,计算当前字符到最后一个字符之间的所有字符所组成的字符串对应的最佳分割得分p。分割得分p的计算公式如下:

step3 通过Step2的不断迭代以及遍历搜索过程,得到p(1),即全字符串的最佳分割得分,对应全字符串的最佳分割方式,即字符串不同位置的最佳分割长度。根据最佳分割方式,对字符串进行分割后输出。
2.最大匹配算法
以正向算法为例。
step1 导入词典,包括分词词典和停用词词典。遍历分词词典,找到最长的词,记录其长度为max_chars。
step2 以max_chars为初始匹配长度,正向扫描,寻找字符串中是否有词典中相互匹配的词语。字符串扫描结束后,匹配长度递减,进行下一轮正向扫描。正向扫描期间若得到匹配词语,则将结果保存。直至字符串中的所有字符都找到对应匹配词语。
3.分词效果展示
分别实现了基于前向和后向最大匹配算法以及贝叶斯算法进行自然于然处理中的分词处理,并将三种方法封装,集成在一个可视化操作界面中。以“我在清华大学打游戏,我很强哦。”为例,测试分词效果。
贝叶斯分词
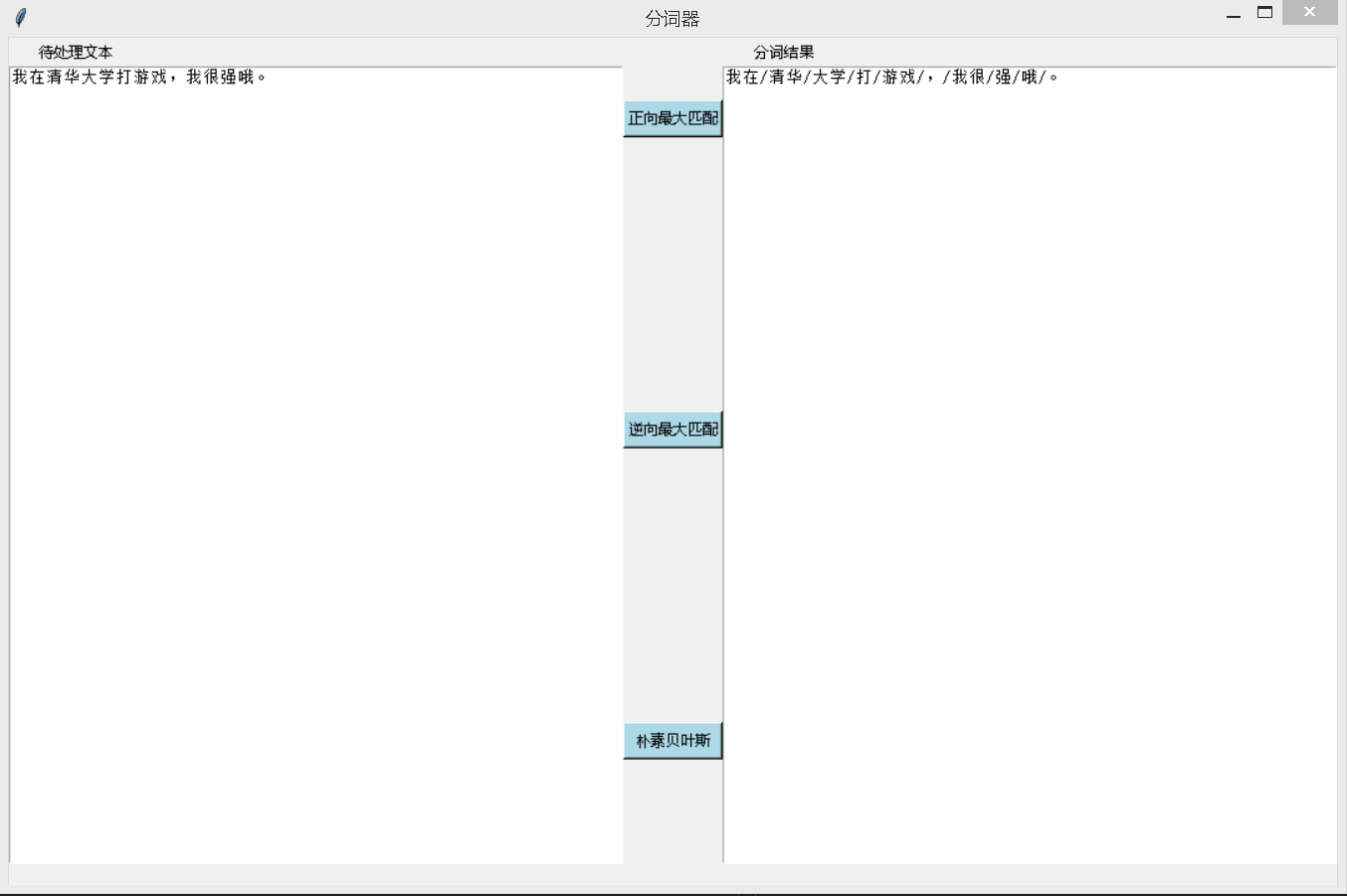
正向最大匹配分词
逆向最大匹配分词
4.源代码
源代码中包括分词算法实现代码以及对应词典。 源代码位于 https://github.com/GeoMTMan/mengmengfenci
感兴趣的朋友可以download学习。